
Figure 1: Review of Video Difference Captioning framework.
Each example in ViDiC consists of a video pair and a fine-grained checklist.
Video A
Video B
Similarity Question: Are the man's clothes different between the two videos?
Correct Answer: No
Difference Question: Does the Source video feature diffuse, cool-toned light, while the Target video features bright, warm-toned backlighting from the upper left?
Correct Answer: Yes
Difference Question: Is the sky in the Source video completely grey and cloudy, in contrast to the Target video where the sky is blue with a visible sun?
Correct Answer: Yes
Video A
Video B
Similarity Question: Do the clothing attributes of the shooter and goalkeeper vary between the Source and Target videos?
Correct Answer: No
Difference Question: Regarding the camera's position, is it true that the Source video is filmed more to the side, while the Target video is filmed from more centrally?
Correct Answer: Yes
Difference Question: Is the building in the background more clearly visible in the Target video compared to the Source video?
Correct Answer: Yes
Video A
Video B
Similarity Question: Are the camera movements between the Source and Target videos different?
Correct Answer: No
Difference Question: Regarding the lighting, is the Source video illuminated by bright, white daylight, in contrast to the Target video which is illuminated by the warm, colored light of a sunrise or sunset?
Correct Answer: Yes
Difference Question: In terms of atmosphere, does the Source video show a blue sky with white clouds, while the Target video shows a sky with warmer colors?
Correct Answer: Yes
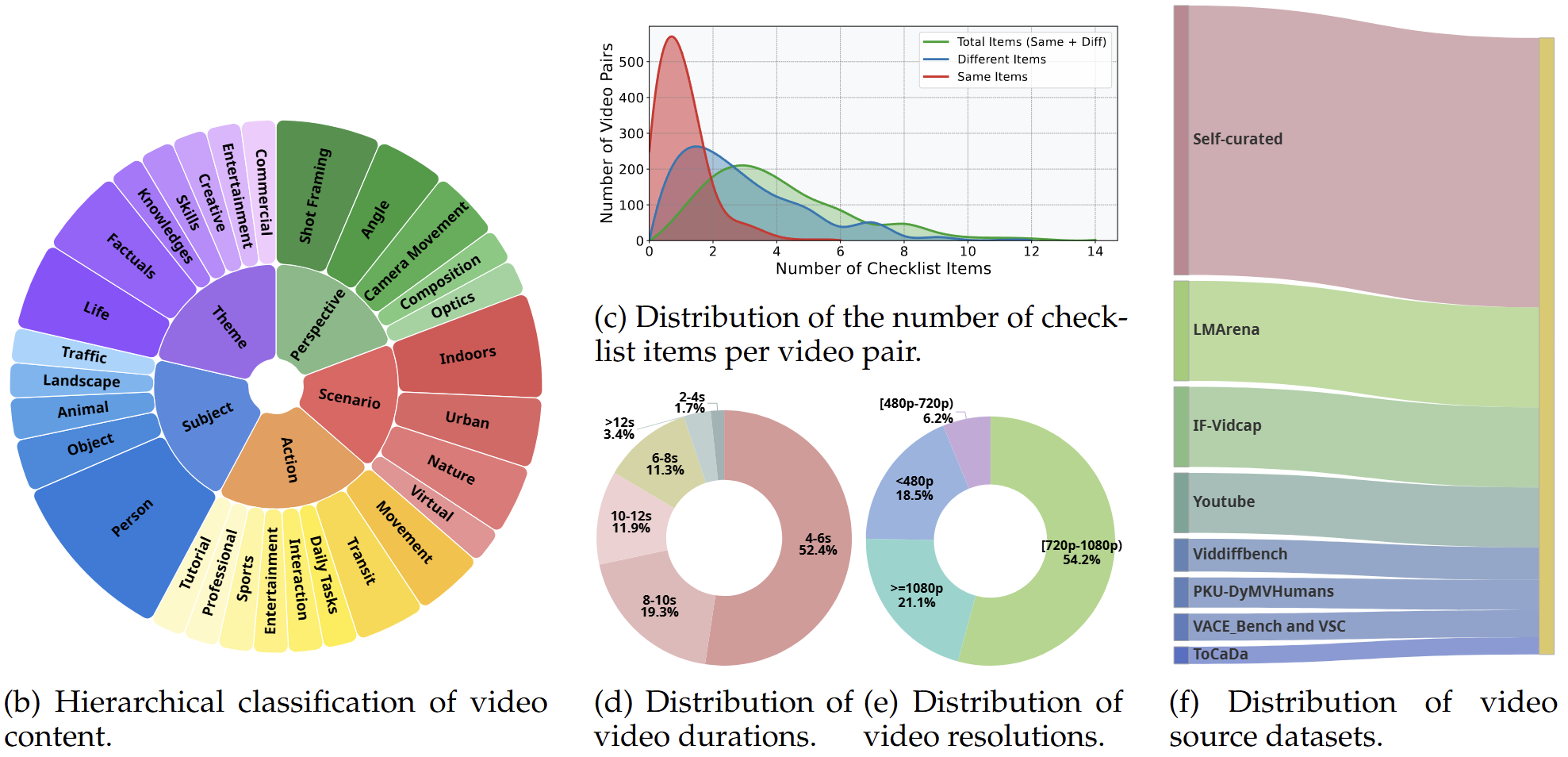
We propose a Dual-Checklist Evaluation Framework to ensure reliable measuring of comparative captioning. Traditional metrics measure textual similarity rather than factual correctness. ViDiC overcomes this by quantifying factual accuracy using a human-annotated checklist composed of binary questions derived from predefined dimensions (Subject, Style, Background, etc.).
We leverage an LLM-as-a-Judge protocol (using GPT-5-Mini or equivalent high-capability models) to compare the generated captions against the ground-truth checklist without accessing the video pixels directly. This ensures scalable and interpretable benchmarking.
@misc{wu2025vidicvideodifferencecaptioning,
title={ViDiC: Video Difference Captioning},
author={Jiangtao Wu and Shihao Li and Zhaozhou Bian and Yuanxing Zhang and Jialu Chen and Runzhe Wen and An Ping and Yiwen He and Jiakai Wang and Jiaheng Liu},
year={2025},
eprint={2512.03405},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.03405},
}